Cara Mendapatkan Banyak Email List Secara Cepat
Cara Mendapatkan Banyak Email List Secara Cepat - Halo teman-teman pada artikel kali ini kami ingin memberikan sebuah tutorial kepada kalian semua yaitu cara untuk mendapatkan banyak email dari website Bing.
Mendapatkan banyak 5 ganti ini memiliki manfaat untuk kita salah satunya yaitu email tersebut bisa kita gunakan untuk spam cc.
Email yang banyak juga bisa kita gunakan untuk database sebagai konsumen kita sehingga kita bisa mengirim pesan ke banyak email tersebut supaya bisa dibaca oleh para penggunanya.
Menggunakan email crawler ini kalian bisa mendapatkan email sebanyak-banyaknya. Tes ini berguna untuk mencari live email sebanyak-banyaknya.
Terserah kalian menggunakan untuk apa spam cc ataupun apapun bebas.
Buat ini menggunakan Python untuk menjalankan perintah perintahnya dan juga untuk menggunakannya kalian sangat mudah sekali yaitu kalau kalian di tembok kalian harus terlebih dahulu dan menginstal beberapa request.
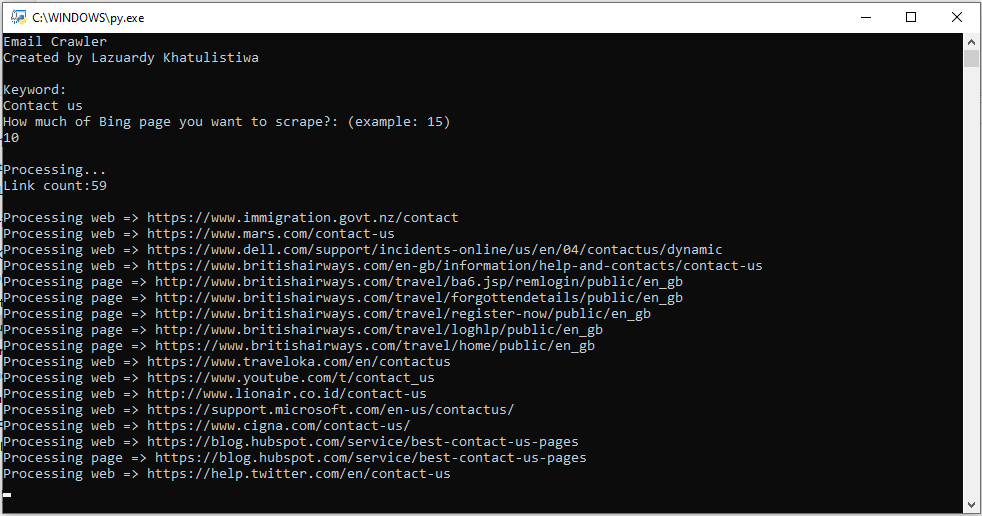 kemudian hasil dari email Crawler tersebut akan tersimpan di result.txt
kemudian hasil dari email Crawler tersebut akan tersimpan di result.txt
Cara Mendapatkan Banyak Email List Secara Cepat | Email Crawler
Berguna buat ngambil email dari hasil pencarian Bing.
- Scrape email berdasarkan link, dan link didalam linknya.
Bahan :
Prerequisites
Python 3
Python library: fake_useragent & requests
Tutorial :
Install python 3
Install fake_useragent & requests library, use pip:
email disimpan di results.txt
Mendapatkan banyak 5 ganti ini memiliki manfaat untuk kita salah satunya yaitu email tersebut bisa kita gunakan untuk spam cc.
Email yang banyak juga bisa kita gunakan untuk database sebagai konsumen kita sehingga kita bisa mengirim pesan ke banyak email tersebut supaya bisa dibaca oleh para penggunanya.
Menggunakan email crawler ini kalian bisa mendapatkan email sebanyak-banyaknya. Tes ini berguna untuk mencari live email sebanyak-banyaknya.
Terserah kalian menggunakan untuk apa spam cc ataupun apapun bebas.
Buat ini menggunakan Python untuk menjalankan perintah perintahnya dan juga untuk menggunakannya kalian sangat mudah sekali yaitu kalau kalian di tembok kalian harus terlebih dahulu dan menginstal beberapa request.
Cara Mendapatkan Banyak Email List Secara Cepat | Email Crawler
Berguna buat ngambil email dari hasil pencarian Bing.
- Scrape email berdasarkan link, dan link didalam linknya.
Bahan :
Prerequisites
Python 3
Python library: fake_useragent & requests
Tutorial :
Install python 3
Install fake_useragent & requests library, use pip:
pip install fake_useragentketik : email-crawler.py
pip install requests
email disimpan di results.txt
import requests
import re
from fake_useragent import UserAgent
import warnings
from requests.packages.urllib3.exceptions import InsecureRequestWarning
print("Email Crawler\nCreated by Lazuardy Khatulistiwa\n")
keyword = input("Keyword:\n")
batas = int(input("How much of Bing page you want to scrape?: (example: 15)\n"))
print("\nProcessing...")
ua = UserAgent(verify_ssl=False)
angka = 1
batas = batas*10
links = set()
emails = set()
email_regex = re.compile('([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})', re.IGNORECASE)
url_regex = re.compile('<a\s.*?href=[\'"](.*?)[\'"].*?>')
while angka < batas:
reqbing = requests.get("https://www.bing.com/search?q="+keyword+"&first="+str(angka), headers={'User-Agent':ua.random})
regexlink = re.findall(r'<h2><a href="(.*?)" h="ID', reqbing.text)
for x in regexlink:
links.add(x)
angka += 10
print("Link count:"+str(len(links))+"\n")
for link in links:
linksin = list()
warnings.simplefilter('ignore',InsecureRequestWarning)
try:
requrl = requests.get(link, headers={'User-Agent':ua.random}, timeout=3, verify=False)
print("Processing web => "+link)
for email in email_regex.findall(requrl.text):
emails.add(email)
try:
for linkcuy in url_regex.findall(requrl.text):
reqlagi = requests.get(linkcuy, headers={'User-Agent':ua.random}, timeout=3, verify=False)
print("Processing page => "+linkcuy)
for email in email_regex.findall(reqlagi.text):
emails.add(email)
except:
pass
except:
pass
print("\nEmail total:"+str(len(emails)))
for imel in emails:
file = open('results.txt', 'a')
file.write(imel+'\n')
file.close()
input("Done.")
Posting Komentar